
 , recken7:
, recken7: 

Louis Verhaard, January 2016
This is a description of poker bot "DaFish" that participated in the Texas Holdem heads-up no limit (aka "HUNL") tournament on http://theaigames.com/competitions/texas-hold-em. The tournament was organized by the Dutch IT company Star Apple.
Around 2003/2004, after amateur Chris Moneymaker won the WSOP main event, there was a poker boom all over the world, and there was a lot of poker on tv. I did not play poker myself (never will) but I enjoyed watching poker.
Intuitively I thought that it should be possible to create a poker program that was better than humans. So in 2004 I wrote a bot that could learn from playing against itself, using a home invented learning algorithm.
This experiment failed miserably. In the beginning my bot became better and better, and at some point it could actually play poker at beginner level. After that, the more it learnt, the tighter (and worse) it became, because once it had learnt that some situation was bad, it would for always shun that situation, even though perhaps that situation was not so bad after all, because the bots judgement of the situation could be based on bad luck. In the end it would sometimes even fold KK preflop.
I tried to fix this, but eventually I concluded that it was a fundamental flaw in my learning algorithm, and I did not find a way out, so I gave up.
When the tournament on theaigames.com started in March 2015 I thought that it would be fun to participate, and perhaps I would be able to take a little revanch on my previous failing.
I downloaded the Java starter bot and played a bit with it, using a hand-crafted heuristic evaluation function that made decisions based on hand strength, position, etc. It felt good, because very soon I had a bot that was way better than the bot from my miserable experiment had ever played.
My bot did quite well and used to be among the top 5 in the competition. But at some point I found it very hard to make substantial improvements, partly because my poker knowledge was too limited. When is it correct to bluff? To check-raise? When to slow play? When to go all-in? I tried to read poker strategy for humans on the net, but it did not help much.
During my research I found that there is an annual tournament for poker bots, www.computerpokercompetition.org. All games that were played (millions!) can be downloaded, so I downloaded all games of the winner of the 2014 HUNL competition, Tartanian 7. Maybe I could learn something from its play?
I ended up writing a program that learnt (again using a home made algorithm) to emulate Tartanian7, although not very accurately, backed up by my old heuristic based program to cover situations for which no Tartanian data was available. This was my version 9.
By this time the opponents at the competition had become better, so my heuristic bot was no longer top 5. But my Tartanian emulator was an improvement and in my opinion it was at that time the second best bot, although a bot named SkelBot was slightly better.
Creating a bot that imitates another bot is of course not very satisfactory, but I learnt a lot from analyzing how Tartanian 7 plays.
I found out that Tartanian 7, and also most other successful bots that were playing at the annual poker bot competition, were based on an algorithm called "Counterfactual Regret Minimization" (CFRM). Well, only the name of this algorithm is deterring enough. But I downloaded Richard Gibson#s Ph. D. thesis http://poker.cs.ualberta.ca/publications/gibson.phd.pdf and tried to understand the algorithm and the theory behind it.
Conceptually it is very simple: just like the algorithm I tried out ten years ago, a bot learns from self play. But the beauty of CFRM is that it has a mechanism that avoids getting stuck in local optima, which was what happened in my previous algorithm. Although the maths are not simple (and I don't claim to understand all details), the algorithm itself can be implemented in under 100 lines of code, and plenty of implementations of CFRM can be found on the net.
The strategy calculated by CFRM will eventually approach a "Nash equilibrium". Simplistically this means that we assume that the opponent knows exactly how we play, so we just try to minimize our losses. So the calculated strategy does not care if our opponent is tight, loose, aggressive or passive, this in contrast to poker strategies that adapt to its opponents and which are based on opponent models.
A challenge is that all the CFRM bots I read about use gigabytes or terabytes of disk space, and their strategy is computed using hundreds or even thousands of computers for months; theaigames.com only allows uploading 2 megabytes of source code and I only have two computers, would that be enough to create a bot that plays well enough?
The only way to find out was to try, so I implemented CFRM and encountered tons of problems, due to bugs, thinking errors and misconceptions (from my side) on the workings of CFRM. Debugging was a nightmare.
For example at some point the bot was raising all the time, no matter how bad cards it had. It took a lot of time to find out that this was due to a bug: after 4 subsequent raises I had put in a limitation that the bot can only fold or call, but I had made an error so in this situation the bot folded always, with disastrous consequences for the strategy calculation.
This was just one of many bugs, and each one was equally difficult to smoke out. Even worse were errors due to bad thinking. But in the end I found most errors. Although I still suspect that I have a small bug left, finally a strategy emerged that was significantly better than the Tartanian 7 emulator.
It is quite cool to see a bot getting better and better the more it plays against itself. And to see the bot bluffing, check-raising, and all that stuff I was wondering about, not because someone has told it to, but because it has computed that this is in fact the best strategy, that is just wonderful:)
For the connaisseurs: I used CFRM with external sampling, it seemed easiest to implement and appropriate for my purposes. I ported a C# implementation from "amax" that can be found on http://poker-ai.org. My model contains a few hundred thousand "information sets"; the computation becomes quite stable after less than a week of CPU time.
BTW, the strategy is completely calculated offline; the DaFish version playing at theaigames.com does not do any major calculation, it just looks up the correct information set in a table and plays according to what it finds there.
A surprising amount of time went into what I much later found out is called "post-processing"; turning the strategy calculated by CFRM into an actual playing poker bot. Actually there is research written on this, see for example https://www.cs.cmu.edu/~sandholm/hierarchical.aamas15.pdf, but I had not read much about this so I ended up reinventing a few mechanisms myself.
I use a similar method as all other CFRM based poker bots I read about use: the CFRM strategy is actually calculated on a significantly simpler, abstract version of poker. As an example, instead of allowing any amount of raise, my CFRM implementation only uses bet sizes 0.25*pot, 0.5*pot, 0.75*pot, 1*pot, 2*pot, and all-in.
So what if the opponent raises 1.5 times the pot size? I used the following heuristic approach: with some probability, based on the logarithm of the raise divided by pot size, I treat the opponents raise either as a pot sized raise or as a 2*pot sized raise. Mostly that works ok. But in some situations this will lead to totally incorrect decisions. And after such a raise, we are in an unfamiliar state (with an unfamiliar pot size) which also negatively affects subsequent decisions in the game. I found out later that this is called the "off-tree" problem and that this is a fundamental weakness of this "simplified poker" approach with no easy way out, see also http://www.cs.cmu.edu/~sganzfri/Claudico15.pdf.
Another problem is that my bot likes to go all-in, also with bad cards. And, as a consequence, it also frequently calls all-in even with marginal hands. Although theoretically this is correct (if we only raise or call all-in with good hands we become too predictable), this leads to an enormous variance in results. So version 11, which played strictly according to the calculated strategy, often lost to weaker bots due to this appetite for all-in.
I spent quite some time to heuristically restrict going all-in/calling all-in without compromising overall game strength too much. Probably I should have restricted it even more.
Finally, I applied "strategy purification". The strategy calculated by CFRM is a mixed strategy. An example: in some situation, the calculated strategy may return: [fold: 0.00, call: 7.60, raise0: 31.52, raise1: 41.30, raise2: 14.13, raise3: 5.43, raise4: 0.00, allin: 0.02 ], meaning, we should call 7.6% of the time, raise 0.25-potsize 31.52% of the time, etc. Usually it is not a good idea to pick an action that has a very small percentage.
In the final version, DaFish always takes the action with highest number, i.e. in the example it will do raise1 100% of the time. Theoretically this will result in exploitable behaviour. In practice it works quite well, DaFish is exploitable anyway.
It was a pity that I first did this purification near the end of the competition; since a pure strategy takes much less space than a mixed strategy I could have added many more CFRM states to the model if I had known this earlier.
Thanks to these post-processing techniques, DaFish plays more small ball poker than the strict CFRM-proposed strategy and obtains much better results against weaker bots. Against a weaker bot it is much better to play a match of 60 games at Elo rating strength 1990 than to play an match of 1 game at Elo 2000 decided by an all-in rollout.
DaFish uses in fact two CFRM models, one calculated for a stack size 50 big blinds/player, and one for a stack size of 30 big blinds.
Version 11 only used the 50 big blind model, but I discovered that the strategy at smaller stack sizes is a bit different. When the blinds get up the money we loose each hand due to inferior strategy can become substantial. Adding the 30 big blind model (which required a lot of squeezing of memory to fit into 2 MB) improved performance in long matches.
When one of the players has a stack size of 10 big blinds or less, it plays push/fold poker based on a table I found on http://www.holdemresources.net/h/poker-theory/hune.html.
The "CFRM DaFish" is much better than the "Tartanian7 Dafish". But also the other competitors had improved, and some new ones arrived that were very strong. At the end of the competition there the top 10 bots (of a total of 145) were roughly equally strong. In the end, DaFish ended in 5th place. American bot ThunderBluff by "cowzow" won the competition.
I am quite pleased with its strength, although I don't have any illusion that it would stand a chance against any of the CFRM bots that participate in the annual poker competition, all of them using at least a million times more information sets than DaFish.
Overall, it was an enormous frustrating experience to develop this poker bot. In the course of this project I have pulled out many of my hairs, and the ones that I have left have become even greyer than they already were. I was about to give up several times, and I asked myself many times "why am I doing this"?
As an upside, I have learnt a lot about how to deal with imperfect information. I also learnt a lot about heads up poker, so yesterday evening I watched the final table of a poker tournament on youtube and could see for myself that the player that finished second was extremely bad at playing heads up:), otherwise I see no advantages of this last skill.
I learnt enough about poker to appreciate the enormous skills of professional poker players. Last year there was a match between 4 top pros and "Claudico", a turbo version of already mentioned Tartanian 7, using a strategy that takes up tens of terabytes of memory + a super computer that calculates river strategy. The humans won! I find this amazing. How do humans do this??
For future work I am a bit curious to see if my approach would work for multi-player games as well. We'll see about that, right now I don't want to think about computer poker for a long while.
Finally I would like to thank Star Apple for the organization of this competition. They have put in a lot of resources in creating and maintaining a very nice competition environment. I can recommend any programmer to join one of their competitions, it is free to enter, you will certainly learn a lot and it is easy to get started using the starter bots that you can download from their web site. There are several different games to choose from, ranging from easy to complex.
A friend of mine asked if a computer generated strategy would sometimes bluff. Yes, DaFish bluffs quite often. From a game DaFish - recken7:
Round 10, dealer: DaFish
Stack sizes: DaFish: 2841, recken7: 1159
DaFish blinds 10, recken7 blinds 20
DaFish: , recken7:
DaFish odds 35.0%, recken7 odds 65.0%
DaFish raises 40; pot is now: 80
recken7 raises 70; pot is now: 190
DaFish calls 70; pot is now: 260


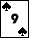 pot: 260
pot: 260DaFish has NO_PAIR/Q+9; hs: 21%; odds 16.9%,
recken7 has PAIR/4+Q; hs: 47%; odds 83.1%
recken7 checks
DaFish raises 195; pot is now: 455
recken7 calls 195; pot is now: 650
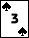 pot: 650
pot: 650DaFish has NO_PAIR/Q+9; hs: 10%; odds 7.1%,
recken7 has PAIR/4+Q; hs: 50%; odds 92.9%
recken7 checks
DaFish raises 162; pot is now: 812
recken7 calls 162; pot is now: 974
 pot: 974
pot: 974DaFish has PAIR/3+Q; hs: 13%; odds 0.0%,
recken7 has TWO_PAIR/4+3; hs: 51%; odds 100.0%
recken7 checks
DaFish raises 2354; pot is now: 3328
recken7 folds
DaFish wins 3328
Phew...
Here follows a rather randomly selected list of games at the end of the competition, mostly against top bots.
2CARDFRAMBO: 2CARDFRAMBO wins after 16 rounds
AKaiAK: AKaiAK wins after 23 rounds
BetterCallSoul: BetterCallSoul wins after 66 rounds
BetterCallSoul: DaFish wins after 42 rounds
dman95_Texas: DaFish wins after 37 rounds
dman95_Texas: dman95_Texas wins after 71 rounds
empassionbot: DaFish wins after 76 rounds
eriktheviking: DaFish wins after 66 rounds
Fierce: DaFish wins after 70 rounds
Likes2Golf_Texas: Likes2Golf_Texas wins after 34 rounds
Likes2Golf_Texas: DaFish wins after 40 rounds
luckman_Texas: DaFish wins after 15 rounds
luckman_Texas: luckman_Texas wins after 76 rounds
PBX: DaFish wins after 15 rounds
QuispelT: QuispelT wins after 41 rounds
recken7: DaFish wins after 22 rounds
SkelBot: DaFish wins after 24 rounds
SkelBot: SkelBot wins after 84 rounds
ThunderBluff: DaFish wins after 24 rounds
ThunderBluff: ThunderBluff wins after 37 rounds